Xuying Zhang 张旭迎AI Researcher at JD Explore Academy
Address: JD Technology Building, Haidian District, Beijing |

|
Biography [back top]
I am an AI researcher at the TGT program of JD Explore Academy, working with Dr. Nan Duan and Dr. Haoyang Huang. Previously, I received my Ph.D. degree from Nankai University, supervised by Prof. Ming-Ming Cheng and Prof. Qibin Hou. Earlier, I obtained my M.S. degree under the supervision of Prof. Rongrong Ji and Prof. Xiaoshuai Sun at Xiamen University. In addition, I worked as a research intern at several AI industrial institutions, such as Kunlun Skywork, Shengshu Technology, Shanghai AI Lab, and JD AI Research.
My research covers a range of Artificial Intelligence and Deep Learning. More recently, I focus on the following aspects:
- Spatial Intelligence.
- World Models and Video Generation.
- Multimodal learning, especially on vision and language.
Latest News [back top]
- 07/2026: One paper was accepted by ACM MM 2026.
- 06/2026: One paper was accepted by ECCV 2026.
- 09/2025: One paper was accepted by NeurlPS 2025.
- 06/2025: Two papers were accepted by ICCV 2025.
- 02/2025: One paper was accepted by IJCV 2025.
- 01/2025: One paper was accepted by TPAMI 2025.
- 08/2024: One paper was accepted by TPAMI 2024.
- 03/2024: One paper was accepted by ICME 2024 as the best paper candidate.
- 02/2024: One paper was accepted by CVPR 2024.
- 01/2024: One paper was accepted by ICLR 2024.
- 05/2022: I passed my master's graduation defense.
- 03/2022: One paper was accepted by CVPR 2022.
- 03/2021: One paper was accepted by CVPR 2021.
- 06/2020: One paper was accepted by ACM MM 2020.
Publications [back top]
* Eauql contribution. ✉ Corresponding author.
Journal
03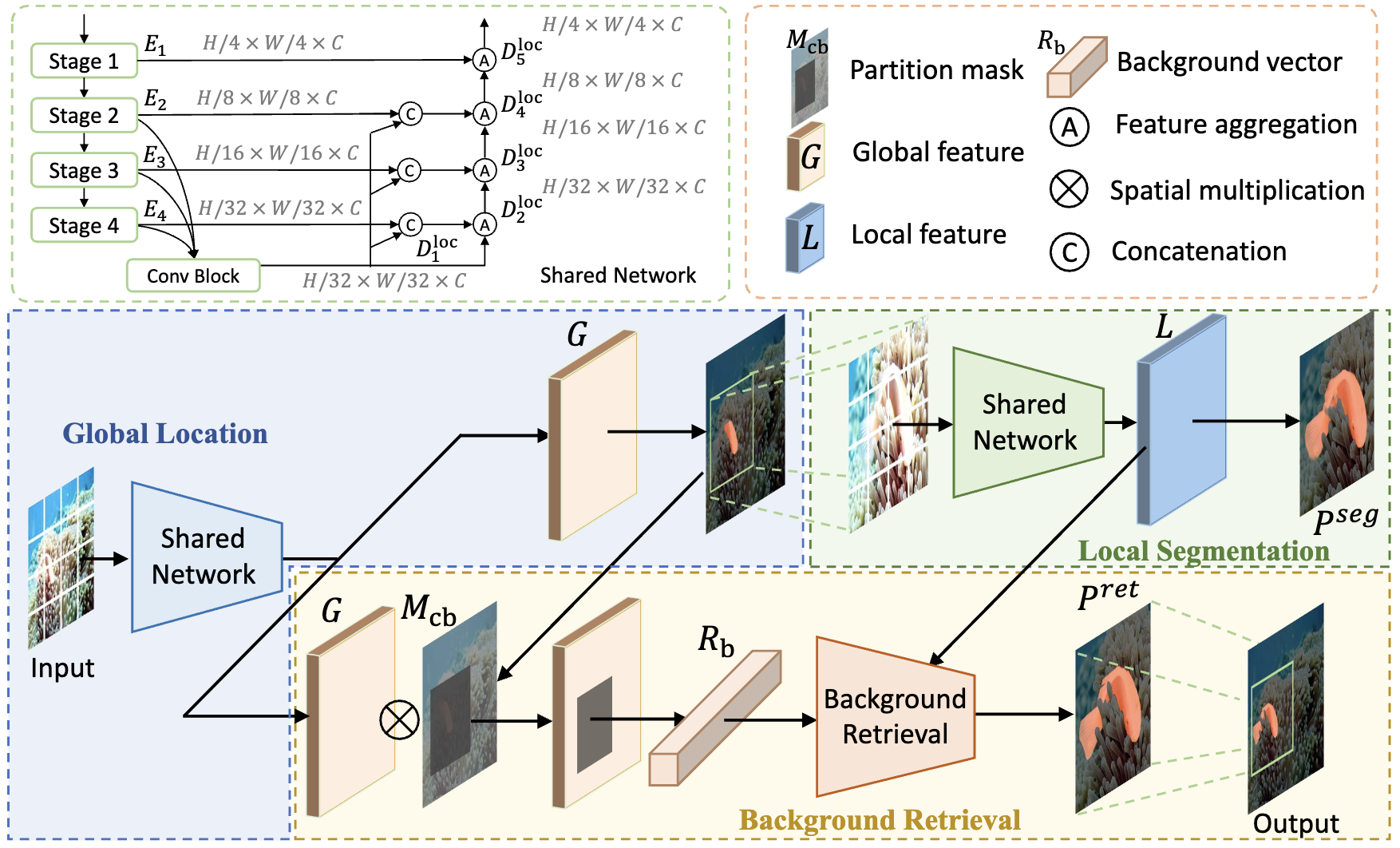 |
Bowen Yin, Xuying Zhang, Li Liu✉, Ming-Ming Cheng, Yongxiang Liu, Qibin Hou✉
Camouflaged Object Detection with Adaptive Partition and Background Retrieval International Journal of Computer Vision (IJCV), 2025, CCF-A [Paper] [Code (  )] )]
|
02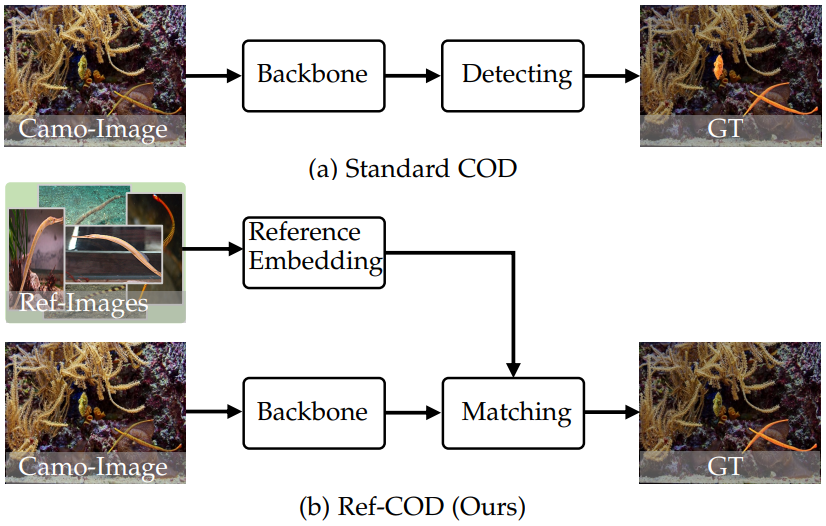 |
Xuying Zhang*, Bowen Yin*, Zheng Lin, Qibin Hou✉, Dengping Fan, Ming-Ming Cheng
Referring Camouflaged Object Detection IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025, CCF-A [Paper] [Code (  )] )]
|
01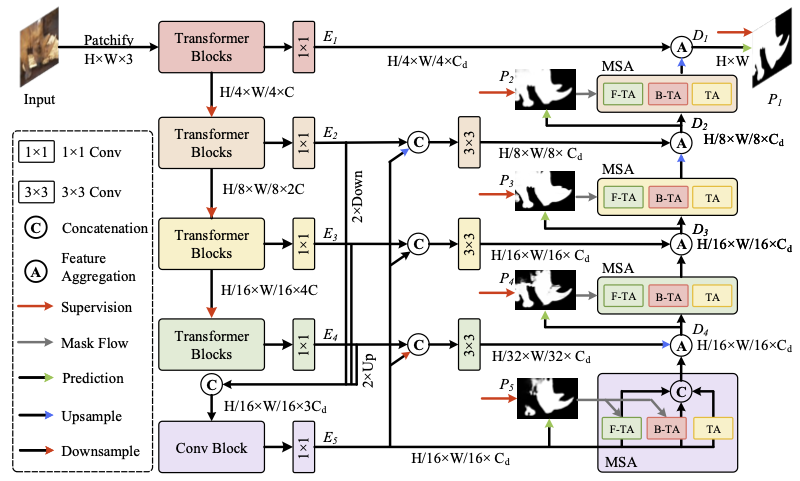 |
Bowen Yin*, Xuying Zhang*, Qibin Hou✉, Boyuan Sun, Dengping Fan, Luc Van Gool
CamoFormer: Masked Separable Attention for Camouflaged Object Detection IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024, CCF-A [Paper] [Code (  )] )]
|
Conference
09 |
Bowen Yin, Jiao-Long Cao, Xuying Zhang, Yuming Chen, Qibin Hou✉, Ming-Ming Cheng.
OmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation Conference and Workshop on Neural Information Processing Systems (NeurlPS), 2025, CCF-A [Paper] [Code (  )] )]
|
08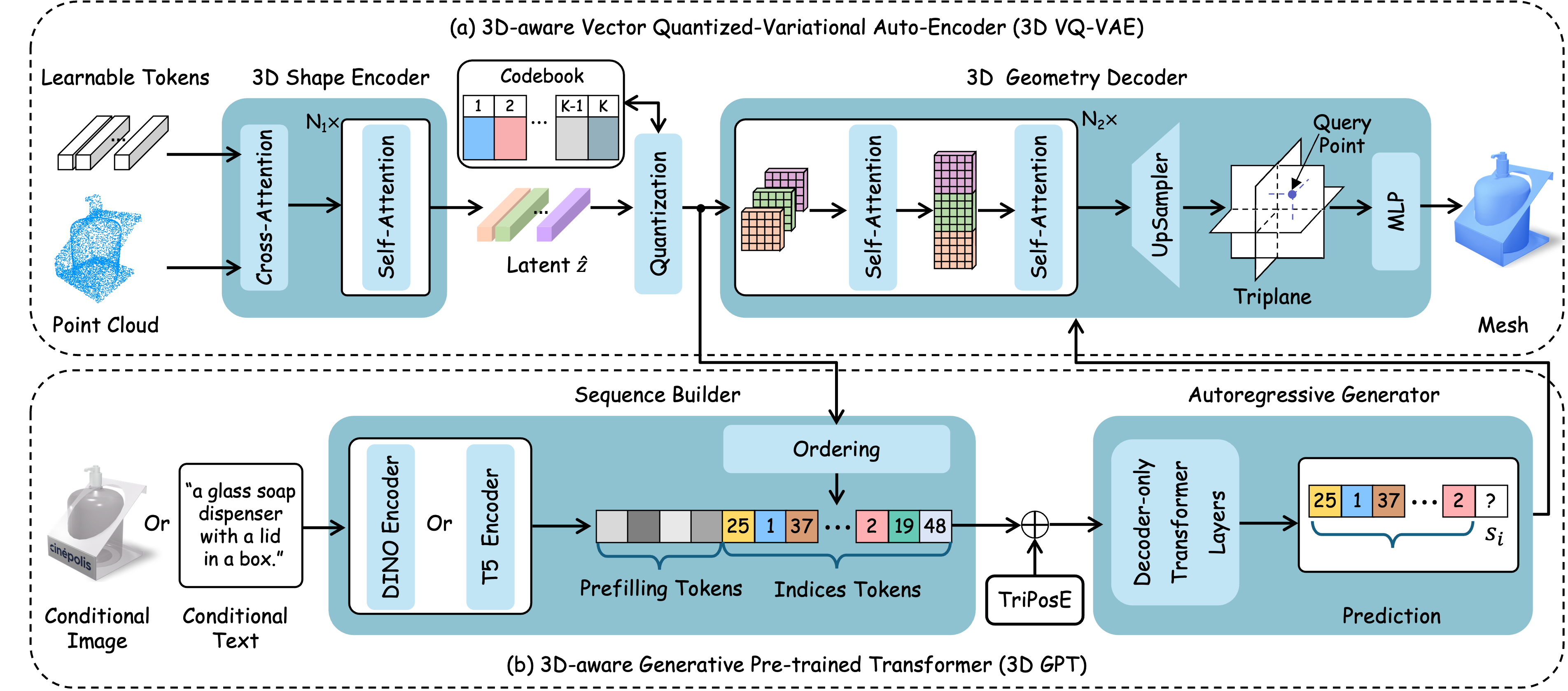 |
Xuying Zhang*, Yutong Liu*, Yangguang Li, Renrui Zhang, Yufei Liu, Kai Wang, Wanli Ouyang, Zhiwei Xiong, Peng Gao, Qibin Hou, Ming-Ming Cheng.
TAR3D: Creating High-Quality 3D Assets via Next-Part Prediction IEEE International Conference on Computer Vision (ICCV), 2025, CCF-A [Paper] [Code (  )] )]
|
07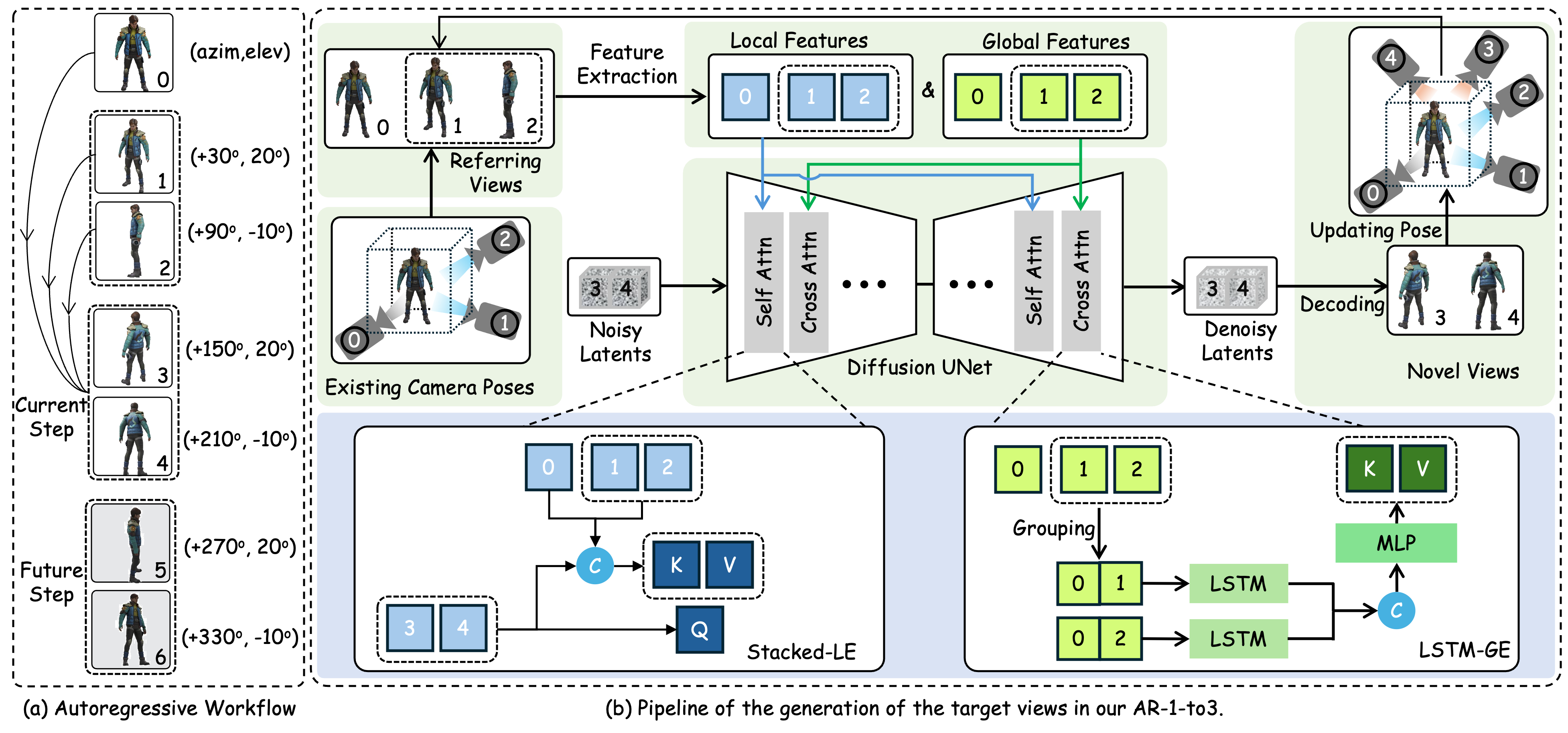 |
Xuying Zhang*, Yupeng Zhou*, Kai Wang, Yikai Wang, Zhen Li, Daquan Zhou, Shaohui Jiao, Qibin Hou✉, Ming-Ming Cheng.
AR-1-to-3: Single Image to Consistent 3D Object Generation via Next-View Prediction IEEE International Conference on Computer Vision (ICCV), 2025, CCF-A [Paper] [Code (  )] )]
|
06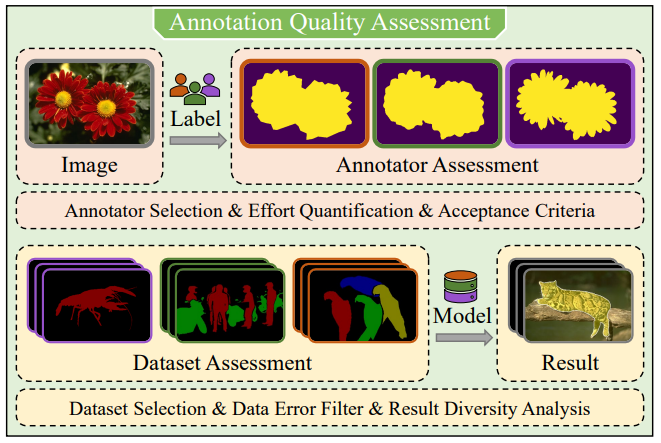 |
Zheng Lin, Zheng-Peng Duan, Xuying Zhang, Luojun Lin
No-Reference Segmentation Annotation Quality Assessment IEEE International Conference on Multimedia and Expo (ICME), 2024, Oral, Best Paper Candidate, CCF-B [Paper] [Code (  )] )]
|
05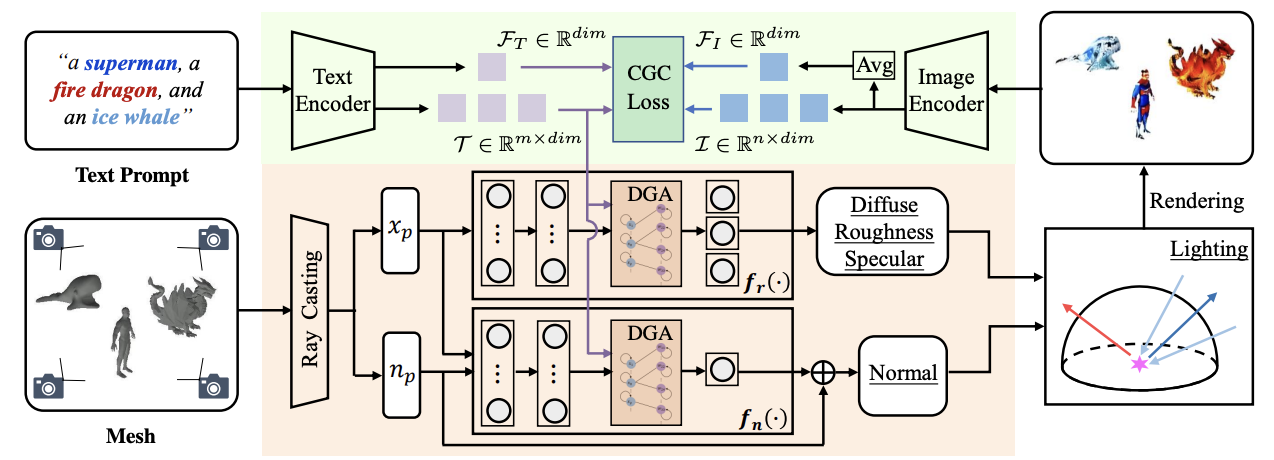 |
Xuying Zhang, Bowen Yin, Yuming Chen, Zheng Lin, Yunheng Li, Qibin Hou✉, Ming-Ming Cheng
TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, CCF-A [Paper] [Code (  )] )]
|
04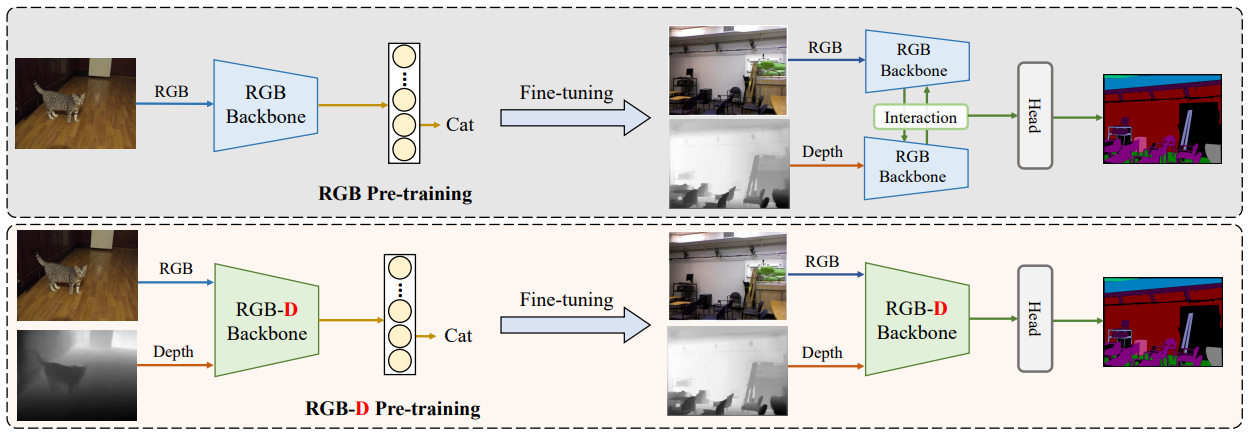 |
Bowen Yin, Xuying Zhang, Zhongyu Li, Li Liu, Ming-Ming Cheng, Qibin Hou✉
Rethinking RGBD Representation Learning for Semantic Segmentation International Conference on Learning Representations (ICLR), 2024 [Paper] [Code ( )]
|
03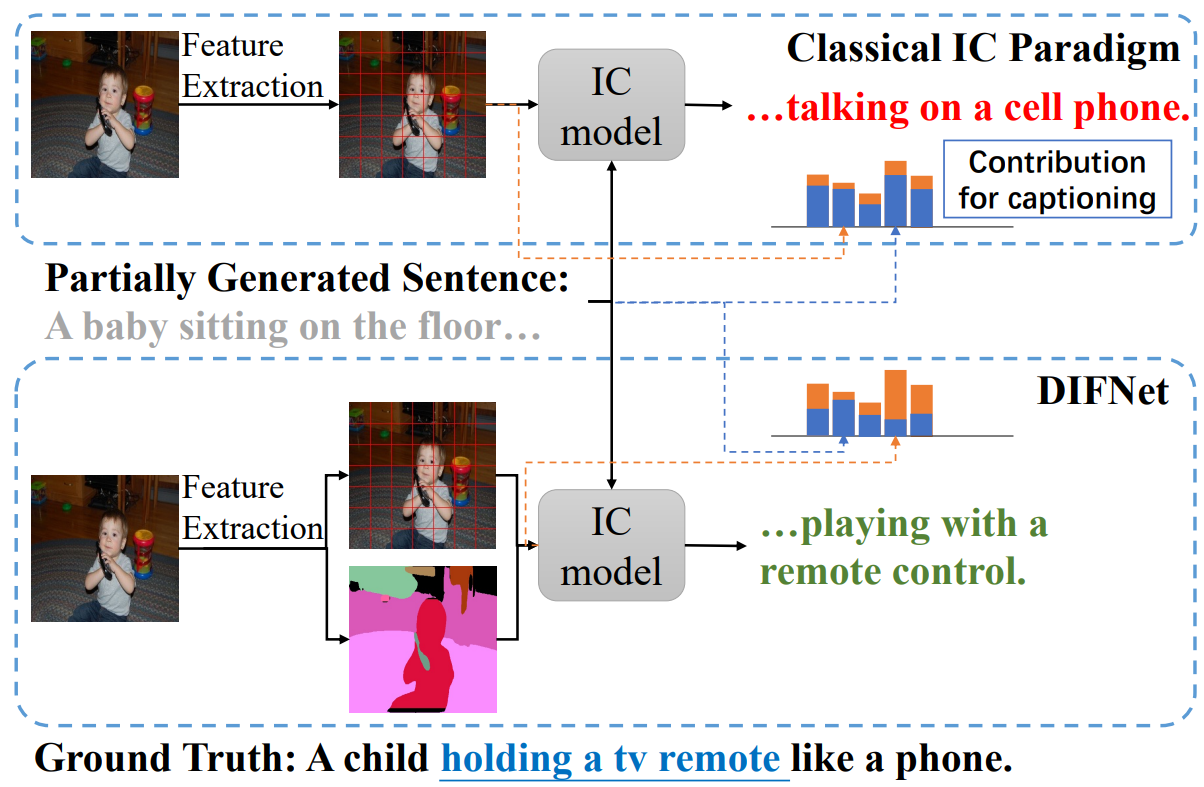 |
Mingrui Wu*, Xuying Zhang*, Xiaoshuai Sun✉, Yiyi Zhou, Chao chen, Jiaxin Gu, Xing Sun, Rongrong Ji
DIFNet: Boosting Visual Information Flow for Image Captioning IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, CCF-A [Paper] [Code (  )] )]
|
02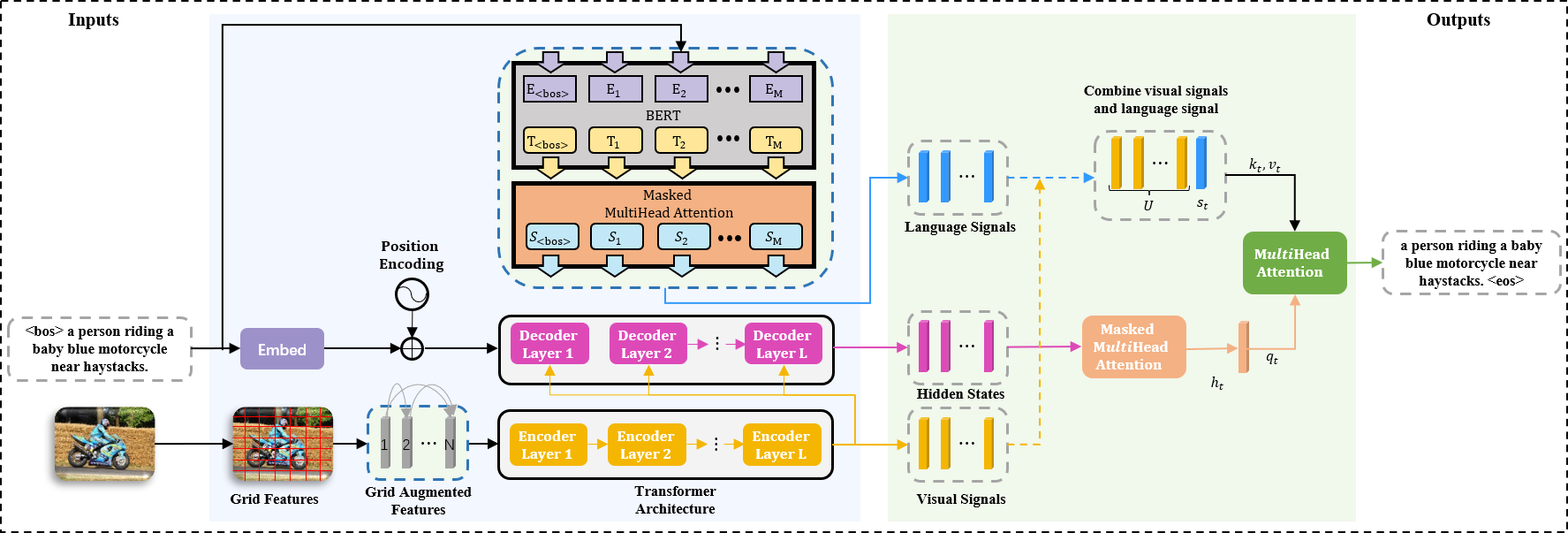 |
Xuying Zhang, Xiaoshuai Sun✉, Yunpeng Luo, Jiayi Ji, Yiyi Zhou, Yongjian Wu, Feiyue Huang, Rongrong Ji
RSTNet: Captioning with Adaptive Attention on Visual and Non-Visual Words IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, CCF-A [Paper] [Code (  )] )]
|
01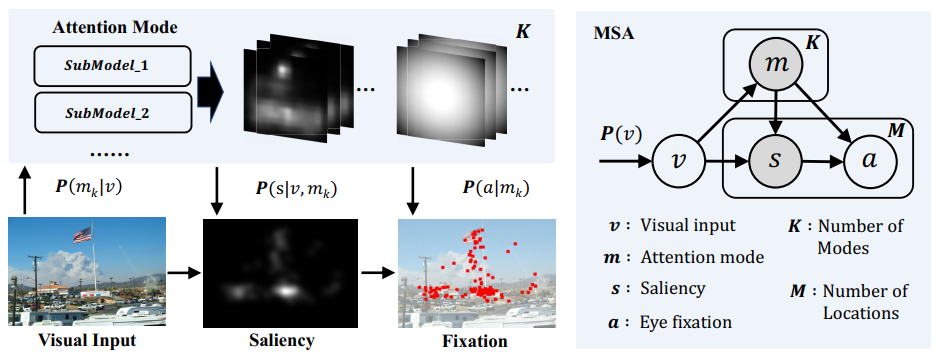 |
Xiaoshuai Sun (supervisor), Xuying Zhang, Liujuan Cao✉, Yongjian Wu, Feiyue Huang, Rongrong Ji
Exploring Language Prior for Mode-Sensitive Visual Attention Modeling Proceedings of the 28th ACM International Conference on Multimedia (ACM MM 2020), CCF-A [Paper] [Code (  )] )]
|
Preprint
01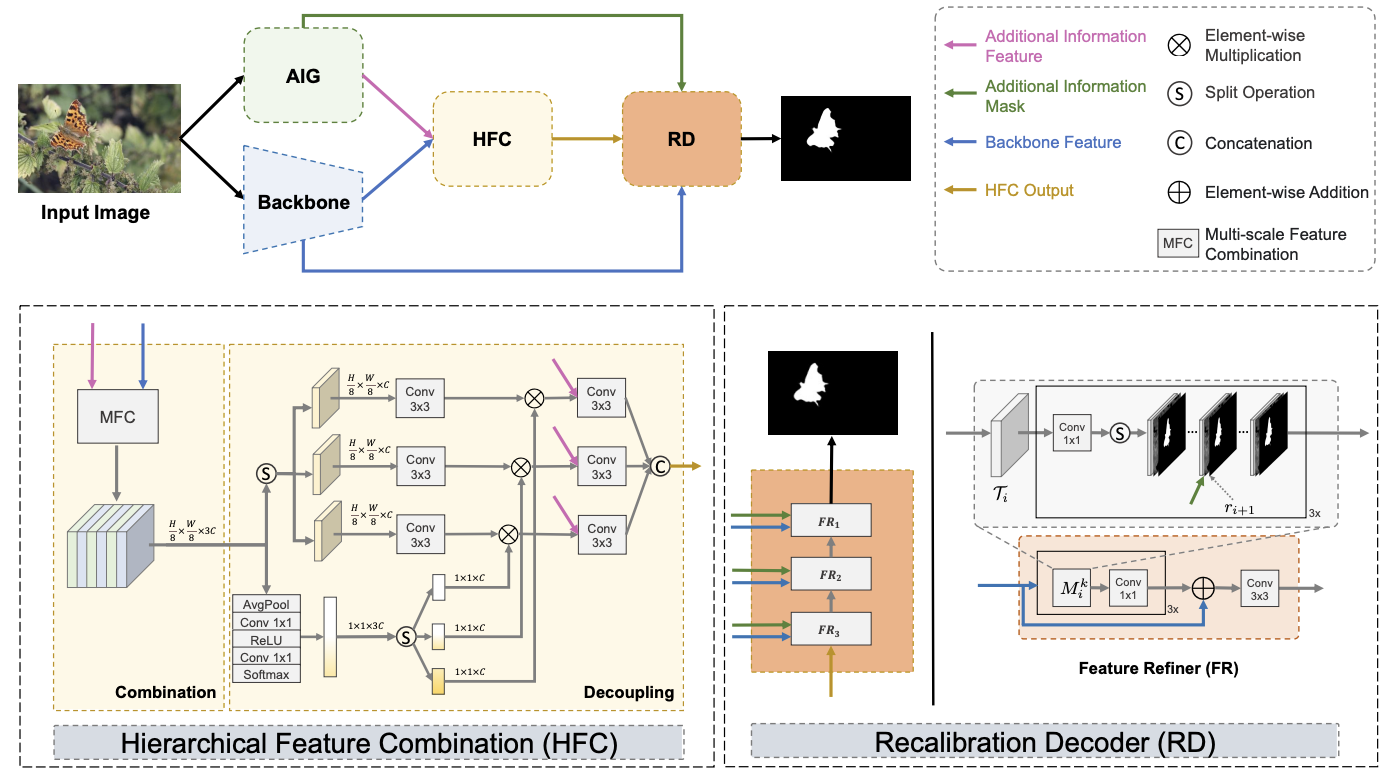 |
Zhennan Chen, Xuying Zhang, Tian-Zhu Xiang, Ying Tai.
Adaptive Guidance Learning for Camouflaged Object Detection arXiv preprint arXiv:2405.02824 (Under Review) [Paper] [Code (  )] )]
|
Thesis
|
03. Research on Predictive Modeling for 3D Content Generation (三维内容生成的预测式建模方法研究) [Undergraduate] |
|
02. Visual Position Embedding and Adaptive Word Measuring for Image Captioning (基于视觉位置编码和动态词性度量的图像自动描述) [Master] |
|
01. Image Feature Detection and Extraction Based on Deep Learning (基于深度学习的图像特征检测与提取) [Undergraduate] |
Professional Activities [back top]
- Conference Reviewer
- IEEE/CVF Computer Vision and Pattern Recognition (CVPR)
- IEEE International Conference on Computer Vision (ICCV).
- European Conference on Computer Vision (ECCV).
- Journal Reviewer
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
- International Journal of Computer Vision (IJCV).
- IEEE Transactions on Image Processing (TIP).
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT).
- Teaching Assistant
- Assembly language programming, Xiamen University, Spring 2021.
Honors & Awards [back top]
- National Scholarship, The Chinese Ministry of Education, 2025.
- Excellent Graduate, Xiamen University, 2022
- National Scholarship, The Chinese Ministry of Education, 2021.
- National Scholarship, The Chinese Ministry of Education, 2020.
- National Second Prize, Contemporary Undergraduate Mathematical Contest in Modeling, 2017.